TH Chat - Der Studienberater der TH Wildau
Häufig verlieren sich Studierende in der oftmals unübersichtlichen Webseitestruktur, um Informationen zu Lehrveranstaltungen, Bewerbungsfristen, Prüfungsordnungen und ähnlichen Themen zu finden. Dadurch werden Hochschulmitarbeiter mit E-Mails überflutet und die allgemeine Unzufriedenheit steigt. Im Rahmen der Wildauer Softwarefabrik haben wir ein Chatbot-System entwickelt, das Studierenden, Mitarbeitenden und Interessierten rund um die Uhr verlässliche Antworten auf ihre Fragen zur Hochschule liefern kann. Unser Chatbot soll schnelle und passende Antworten auf Basis der zugrundeliegenden Inhalte liefern und somit sowohl Studierenden als auch Mitarbeitern dabei helfen, problemlos an benötigte Informationen zu gelangen. Durch die Nutzung von Studien- und Prüfungsordnungen, Modulhandbüchern und dem offiziellen Stundenplan kann er gezielt Antworten generieren und somit innerhalb von Sekunden bei der Suche von Informationen helfen.
Herausforderungen für das Projekt
Natürlich lief nicht alles von Anfang an rund.
Team & Zeitmanagement:
Es war unser erstes größeres Projekt mit sieben Personen. Gerade am Anfang war es nicht leicht einzuschätzen, wie viel in einen Sprint wirklich passt, wann die Tickets fertig sein müssen und wie viel jedes Teammitglied in zwei Wochen wirklich bearbeiten kann. Im zweiten Semester waren wir dann nur noch zu fünft. Das bedeutete: Aufgaben & Teamrollen neu verteilen, Verantwortlichkeiten klären und ursprüngliches Projektziel so anpassen, dass es realistisch bleibt.
Umgang mit LLMs & Deployment:
Mit lokal laufenden Sprachmodellen hatte kaum jemand von uns praktische Erfahrung. Prompting, Finetuning, sinnvolle Kontextbegrenzung; vieles war Try & Error und nahm mehr Zeit in Anspruch als gedacht. Selbst jetzt nach 2 Semestern ist das Endergebnis noch lange nicht perfekt. Auch das Deployment im Hochschulnetz war Neuland, nicht nur für uns, sondern teilweise auch für die Dozenten.
Projektumfang realistisch halten:
Im ersten Semester kam schnell kam die Frage auf: Was wollen wir alles implementieren, und was ist im gegebenen Zeitrahmen wirklich machbar? Fehlende Erfahrung sorgte vor allem in den ersten Wochen für einige lange Abende. Wir mussten lernen, Features bewusst zu priorisieren, Dinge auch mal wegzulassen und den Projektrahmen nicht zu sprengen. Auch jetzt haben wir noch viele Ideen, die wir gerne umgesetzt hätten.
Herangehensweise
Schnelle Themenfindung
Die Wahl des Themas erfolgte schnell. Das Thema passt fachlich, ist praxisnah und bietet genug technische Tiefe für zwei Semester. Von Seiten der Dozenten erfuhren wir, dass auch die Hochschule Interesse an der Umsetzung hätte. Somit war die finale Entscheidung einfach.
Wissensbasis aufbauen
Bevor wir richtig loslegten, nahmen wir uns bewusst genug Zeit, die Grundlagen zu klären: Wie funktionieren LLMs? Was ist RAG? Wie arbeiten Vektordatenbanken? So sind wir mit einem gemeinsamen Basisverständnis in die Entwicklungsphase gestartet.
Klare Aufteilung im Team
Wir haben das Team früh in drei Bereiche strukturiert: Backend, Frontend und DevOps. Innerhalb dieser Bereiche wurden die Aufgaben weiter unterteilt - z.B. Persistierung der Chats, QOL-Features, Vektordatenbank, Testing, UI-Design, etc. So hatte jeder einen klaren Verantwortungsbereich, und wir konnten parallel arbeiten, ohne uns ständig gegenseitig auszubremsen.
Scrum & Code Reviews
Wir haben Scrum nicht nur als Planungsmethode genutzt, sondern auch fürs Teambuilding. Regelmäßige Meetings haben geholfen, Probleme früh anzusprechen und Wissen zu teilen. Über GitLab-Code-Reviews haben wir Qualität gesichert und voneinander gelernt.
Zwei Phasen: Erst Proof of Concept, dann Skalierung
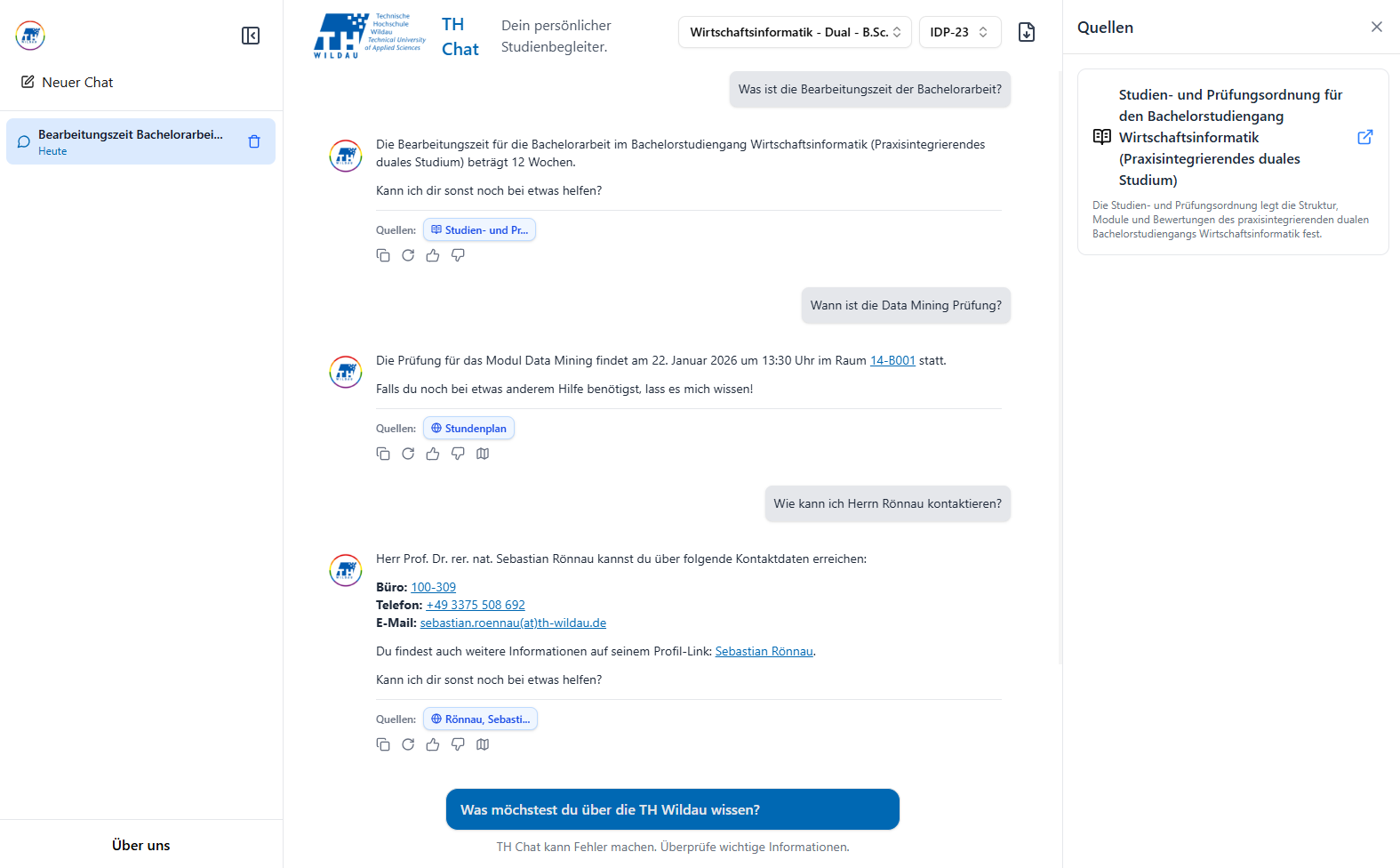
Im ersten Semester lag der Fokus klar auf einem funktionierenden Proof of Concept: Eine ausgewählte, überschaubare Datenbasis und begrenzte Funktionalität. Hauptsache, das System läuft stabil und liefert sinnvolle Antworten. Im zweiten Semester ging es dann ums Skalieren. Das Einlesen von rund 900 Hochschuldokumenten, das Deployment im Hochschulnetz sowie zusätzliche Features wie die Anbindung von Stundenplan und Campus-Karte sollten die Grundlage dafür bilden, dass unser Projekt nicht im Archiv der Hochschule verschwindet, sondern offiziell als Hochschulchatbot genutzt werden kann.
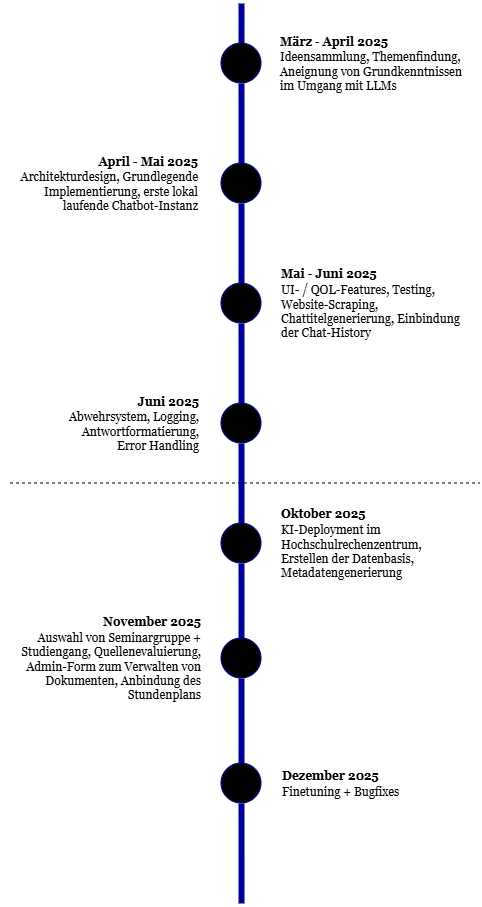
Lösung
Frontend
Als Grundlage für die Benutzeroberfläche haben wir ein modernes und zugleich schlankes Setup gewählt. Mit Hilfe des Web-Frameworks Next.js haben wir wichtige Features wie Kopier- und Exportfunktionen sowie eine Seitenleiste zur schnellen Navigation zwischen den einzelnen Chats implementiert, und orientierten uns am Design der bereits vorhandenen KI-Sprachmodelle.
Backend
Retrieval Augmented Generation (RAG)
Der Chatbot basiert auf dem Prinzip der Retrieval Augmented Generation (RAG): Dabei wird eine Nutzeranfrage zunächst in ein sogenanntes Vektor-Embedding, eine mathematische Repräsentation des Textes, umgewandelt und in einer Vektordatenbank mit zuvor gespeicherten Dokumenten und Webseiteninhalten abgeglichen. Relevante Textpassagen werden extrahiert und dem Sprachmodell als kontextuelle Basis zur Generierung der Antwort übergeben. So entstehen präzise und aktuelle Antworten, ohne dass das Modell selbst neu trainiert werden muss. Das Sprachmodell läuft dabei lokal auf dem Server des Hochschulrechenzentrums und ist über eine API erreichbar. Zur technischen Umsetzung haben wir Python genutzt.
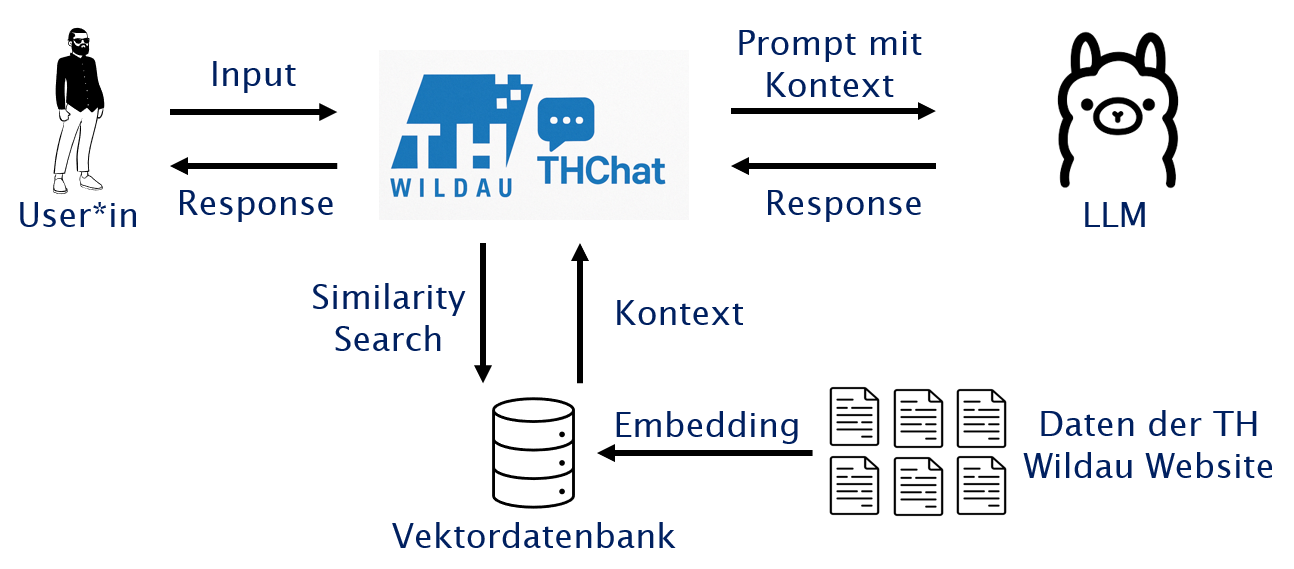
Informationsspeicherung in der Vektordatenbank
Die Speicherung der Informationen in der ChromaDB-Vektordatenbank erfolgt schrittweise:
- Wir nutzen einen PDF-Reader bzw. Webseite-Scraper zum Extrahieren der Texte,
- teilen diese Texte in inhaltlich zusammenhängende Paragraphen ("Chunks") auf und
- speichern sie mit Hilfe eines Vektor-Embedding-Sprachmodells als mathematische Repräsentation in Form von Vektoren in der Datenbank.
Dadurch können wir die Infomationsgrundlage in Form der eingelesenen Dokumente bzw. Webseiteninhalte selbstständig festlegen und so bestimmen, welche Anfragen der Chatbot korrekt bearbeiten kann.

Antwortgenerierung
Für die Generierung der Antwort wird ein individualisierter Prompt genutzt, der nicht nur den aus der Vektordatenbank extrahierten Kontext enthält, sondern auch relevante vorherige Chatnachrichten. Auf diese Weise kann das Sprachmodell konsistente, verständliche und kontextuell passende Antworten liefern.
Datenspeicherung
Für die Verwaltung der Chatverläufe nutzen wir eine PostgreSQL-Datenbank, die Session-Verwaltung erfolgt mit Redis.
Testing
Um die Qualität des Chatbots zu verbessern, haben wir ein automatisiertes Testsystem mit pytest gebaut. Vordefinierte Fragen werden dabei automatisch gestellt und die Antworten mithilfe des LLMs mit Idealantworten verglichen und auf einer Skala von 1-5 bewertet. So konnten wir schnell sehen, ob neue Features die Antworten verbessern oder verschlechtern und gleichzeitig unseren Fortschritt messbar machen.
Finale Features
Fazit
In nur zwei Semester haben wir ohne jegliche Vorkenntnisse einen funktionierenden Chatbot für die Hochschule entwickelt. TH Chat läuft stabil, verarbeitet große Datenmengen und liefert hilfreiche, kontextbezogene Antworten; genau das, was wir erreichen wollten. Perfekt ist das System natürlich nicht, aber für unser erstes Projekt in dieser Größenordnung sind wir mit dem Ergebnis mehr als zufrieden. Die Arbeit war nicht immer einfach, gerade technische Hürden, Abstimmungen im Team und Zeitdruck haben uns gefordert. Trotzdem hat das Projekt durchgehend Spaß gemacht. Wir konnten viel ausprobieren, Neues lernen und als Team zusammenwachsen. Natürlich hätten wir gerne noch mehr Features umgesetzt und noch weiter optimiert. Aber ein wichtiger Teil des Projekts war auch zu lernen, realistische Grenzen zu setzen und den Rahmen bewusst einzuhalten. Wir sind gespannt, was mit TH Chat in der Zukunft passiert und hoffen, dass euch TH Chat den Studienalltag etwas erleichtert.